

Guía de Expresiones Regulares (Regex) con Ejemplos Prácticos
Una de las habilidades que todo desarrollador RPA debería aprender para manipular textos


Hola, por acá Daniela 👋
Bienvenido a una nueva edición de Robotipy. En este post finalmente aprenderás como manipular textos utilizando expresiones regulares.
Si quieres recibir estas publicaciones desde tu correo electrónico, te invito a suscribirte.
Algo que la mayoría de los programadores coinciden sobre las expresiones regulares es que parece ser horrible y da miedo, pero una vez que lo aprendes adquieres un superpoder.

Aún no soy experta ni se todo sobre regex, pero luego de estar unos meses batallando extrayendo información de diferentes PDFs, he decidido escribir esta guía con lo que he aprendido.
Así que, en este articulo, explicaré que son las expresiones regulares enseñando ejemplos y casos de uso. Además te mostraré un ejemplo de como aplicarlo en Python.
¿Qué son las Expresiones regulares (RegEx)?
Considerando que un texto es una secuencia de caracteres (letras, números y otros símbolos), una expresión regular es una forma de encontrar una secuencia de caracteres contenida en un texto que sigue un patrón específico.
En cómputo teórico y teoría de lenguajes formales, una expresión regular, también son conocidas como regex o regexp, por su contracción del inglés regular expression, es una secuencia de caracteres que conforma un patrón de búsqueda. Se utilizan principalmente para la búsqueda de patrones de cadenas de caracteres u operaciones de sustituciones.
Fuente: Wikipedia
Las expresiones regulares son soportadas en la mayoría de los lenguajes de programación, editores de texto e incluso las podemos utilizar en Word.
Aplicaciones de las expresiones regulares
🔍Búsqueda de texto: Encontrar todas las coincidencias de una cadena de texto específica en un documento.
✅Validar patrones: En un formulario definir el formato de un correo electrónico, número de celular, documento de identidad y evaluar si el formato ingresado por el usuario es válido.
⛏️Extracción de información: Extraer información de un documento, como correos electrónicos, datos de una factura, etc.
🤝Reemplazo de texto: Mediante regex reemplazar rápidamente todas las coincidencias en un texto.
Como leer y escribir expresiones regulares
Para aprender a escribir expresiones regulares, tienes que entender el significado de los caracteres que contiene. Si vas a Regex101 verás que existen un montón de simbolos y grupos que podrían abrumarte, mejor empecemos con los más útiles
💡No necesitas aprenderte todo de memoria, puedes volver a esta guía cada vez que lo necesites
1. Caracteres literales
Los caracteres más simples en una RegEx son los caracteres literales, ya que su significado es el mismo que utilizamos cuando leemos un documento.
Los caracteres literales son las letras, números y algunos simbolos que no tienen un significado especial. Son case sensitive, lo que quiere decir que una letra en mayúsculas no es lo mismo que una letra en minúsculas A != a
Si queremos buscar la palabra RPA en un documento, escribiremos lo siguiente

2. Metacaracteres
Los metacaracteres son caracteres que tienen un significado especial en Regex. Pueden tener uno o más significados y nos ayudarán a agregar reglas a nuestras búsquedas.
. ^ $ * + ? { } [ ] \ | ( )
Estos metacaracteres pueden clasificarse en los siguientes grupos:
Comodín (.)
Este metacaracter se utiliza para reemplazar cualquier otro caracter y se simboliza con un punto "."
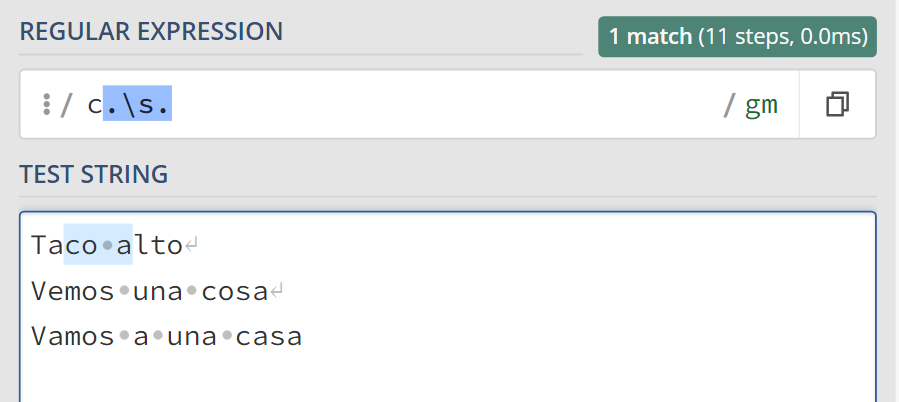
En el ejemplo a continuación, se utiliza para encontrar en cada frase, cualquier palabra que empiece con c, luego siga cualquier caracter, continua con una s y después nuevamente cualquier caracter

Escape de Secuencia (\)
Este metacaracter se utiliza para cambiar el significado del caracter que le continúa y se utiliza el simbolo slash invertido "\".
Si es un caracter especial, lo convierte en un caracter literal y lo mismo al revés. Si es un caracter literal, lo convierte en un caracter especial.
Si se agrega un \ al caracter especial del ejemplo anterior, este deja de ser un comodín y adquiere su significado literal, por lo tanto, ya no ecuentra coincidencia en las palabras cosa o casa, pero si lo hace con c.s.
El carácter especial . (punto) ahora tiene un significado literal. Solo es un punto

En cambio, si al ejemplo del comodín se le agrega un slash invertido (\) a la letra s, esta pierde su significado literal y adquiere un significado especial. En este caso, representa un espacio (\s = space)
La s deja de ser literal una s, ahora tiene otro significado (un espacio)
Algunos caracteres literales escapados que más se utilizan.
\w : Búsqueda de caracter alfanumérico, sirve para buscar un caracter de la "a" a la "z", de la "A" a la "Z", del 0 al 9, incluso un _ (guion bajo)
\d : Búsqueda de un dígito, números del 0 al 9.
\s : Coincide con un espacio en blanco.
\n: Representa los saltos de línea
\t: Representa las tabulaciones
💡Algunos de esos caracteres, al usarlos en mayúsculas, representan lo contrario, \W, \D, \S. Estos carácteres representan los NO alfanuméricos, NO digitos y NO espacios en blanco respectivamente
Cuantificadores
Estos caracteres especifican cuántas veces debe coincidir un caracter o grupo de caracteres.
* : El asterisco indica que el caracter anterior al asterisco puede encontrarse cero, una o más veces. En el ejemplo, \w* se lee como: "Cualquier caracter alfanumerico repetido cero, una o más veces"

Notar que en las líneas sin texto, también hace match, porque es un \w que no existe y el * encuentra desde cero, una o más coincidencias
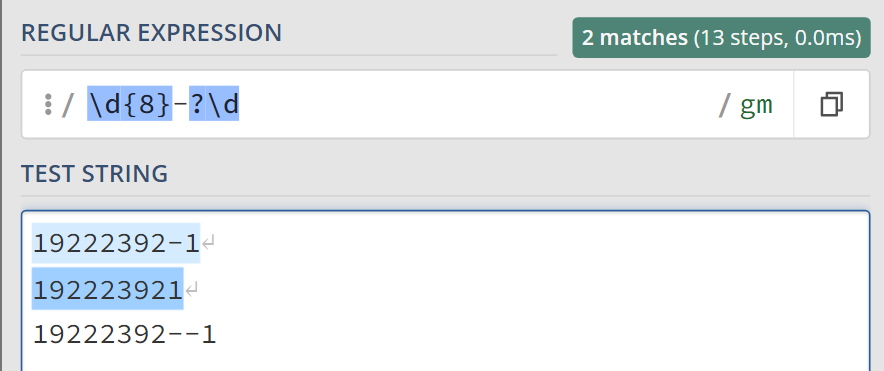
? : Este simbolo indica que el caracter anterior al ?, se puede encontrar una vez o no encontrarse, puede haber cero o uno. En el ejemplo, \d{8}-?\d se lee como: "Ocho digitos, luego un guión que puede estar o no, luego un digito"
+ : El símbolo "más", indica que el caracter que lo acompaña, tiene que existir al menos una vez, puede estar 1 o más veces. El ejemplo se lee como: "La palabra hol (o los caracteres h, o, l) seguido de una
aque puede estar una o más veces"
{N} : Los símbolos "{" y "}", se utilizan para indicar la cantidad de veces que se tiene que repetir un caracter o un grupo de caracteres. Utilizando {3} indicamos que el caracter que le precede, se repite exactamente 3 veces.
En el ejemplo con "?", utilizamos {8} para indicar que los digitos se repiten 8 veces.

Si queremos indicar un número mínimo de veces, podemos agregar una coma luego del número {N,}: N o más veces (donde N es un número). En el ejemplo, podemos utilizarlo en números de telefonos, donde puede haber 11 o más digitos

y si quisieramos indicar un rango, podemos agregar un número antes de cerrar la llave {N,M}: Entre N y M número de veces (donde N y M son números y N < M)







Otros metacaracteres
| : Significa alternancia u "o" , se utiliza para encontrar un valor u otro, ejemplo “a” o “b”.
3. Clases
Las clases son una forma de definir un conjunto de caracteres que deseas encontrar y son creadas con la ayuda de "[ ]" . Estos buscan un carácter que cumpla con lo que este dentro de los corchetes. Podemos leerlo como un "o" multiple
Por ejemplo:
[abc] : quiere decir que el carácter a buscar puede ser "a", "b" o "c".
También podemos definir rangos de búsqueda utilizando el guión "-"
[0-6] : representa todos los números del 0 al 6.
[A-Z] : busca todos los caracteres desde la “A” a la “Z” en mayúsculas.
Las clases son útiles cuando necesitamos que nuestra expresión pueda encontrar un caracter que puede tener diferentes valores.
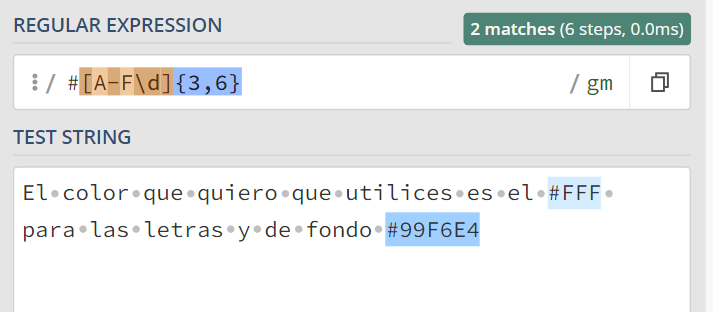
Supongamos que necesitas extraer los colores en formato hexadecimal de un texto, este formato puede contener números del 0 al 9 y letras de la A a la F, por lo tanto utilizaremos el siguiente regex — #[A-F\d]{3,6} — Leído en lenguaje humano sería: "Una secuencia que comience con #, luego cualquier caracter que sea A, B, C, D, E, F o digito y que este se repita 3, 4, 5 o 6 veces"
Negación de clases
Al igual que con las metacaracteres, en las clases podemos "negar" o encontrar algo que signifique lo contrario a lo escrito utilizando el simbolo ^. Cuando utilizamos este caracter al inicio de una clase "[]" de caracteres niega la clase.
Por ejemplo
[^a-z]coincide con cualquier caracter que NO sea una letra minúscula.
4. Grupos
Los grupos, como su nombre lo indica, nos permiten agrupar un conjunto de caracteres dentro de mi expresión regular, para poder extraer la parte especifica de la información que me interesa. Se definen con parentesis "( )" y a diferencia de una clase, esta la podemos leer como un "y" multiple
En este ejemplo, tenemos un texto que es una lista de blogs con sus nombres, contenido y año de publicación y solo nos interesa obtener el nombre especifico del blog.
Sabemos que el nombre viene despues de la palabra “Nombre: ” por lo tanto nuestra expresión regular debe empezar de esa forma, seguido de
\w*que representa un conjunto de cero o mas caracteres (también puedes usar\w+), pero como solo queremos extraer el nombre del blog sin la palabra inicial "Nombre: " creamos un grupo cerrándolo entre paréntesis"( )".

👀 Vemos que el Regex nos selecciona 2 grupos diferentes, el grupo 0 seria el Regex completo y el grupo 1 sería el grupo específico descrito entre
“( )”.
Para extraer un grupo en especifico con lenguajes de programación como Python 🐍 puedes usar el siguiente código:

5. Anclas
Se utilizan para indicar el inicio y final de una línea.
^ : Este carácter tiene doble funcionalidad que difiere cuando se utiliza individualmente y cuando se utiliza con una clase, como lo vimos anteriormente.
Se utiliza como un Startswith, o un "Comienza con" e indica el inicio de una texto
$ : Este caracter, como contraparte del anterior, representa el final de la texto.
Cuando se utilizan en conjunto sirven para asegurar que la coincidencia es de la línea completa.
^Hola.*: coincidirá con cualquier cadena de texto que comience con “Hola”, por ejemplo, "Hola, ¿Cómo estás?", pero no con "¿Hola, estás?", porque el segundo caso “Hola no está al inicio de la cadena.

.*mundo$: coincidirá con cualquier cadena de texto que termine con "mundo". Por ejemplo, coincidirá con "Hola, mundo" pero no con "Hola, mundo!" porque en el segundo caso "mundo" no está al final de la cadena.

^Hola.*mundo$: Al utilizar ambos caracteres juntos, la expresión solo coincidirá con cadenas de texto que sean exactamente “Hola mundo”.

Ejemplos de Expresiones regulares
📱Número de teléfonos
Para los números de telefonos, tenemos que crear combinaciones de digitos que pueden contener o no espacios y puede contener o no un guión. Viendo el caso de número móvil de Chile, tenemos que:
Creamos diferentes grupos
()para extraer código de país, código de red (fija o móvil) y número de teléfonoCada grupo puede estar o no separado por un espacio
\s?Creamos un grupo de dos digitos para extraer el código del país
(\d\d)Creamos un grupo para extraer el tipo de red, esta puede ser de uno o dos digitos
(\d{1,2})Finalmente creamos un grupo para extraer el resto del número que puede ser de 8 o más y puede contener un guión
([0-9\-]{8,})
Chile: (\d\d)\s?(\d{1,2})\s?([0-9\-]{8,})
Colombia: (\d\d)\s?(\d{3})\s?([0-9\-]{7})
Argentina: (\d\d)\s?(\d)\s?([0-9]{4})\s?([0-9\-]{7})
México: (\d\d)\s?(\d)\s?([0-9]{2})\s?([0-9]{4})\s?([0-9]{4})
📅 Fechas
La mayoría de las fechas tienen el formado dd*mm*yyyy, donde * puede ser un punto, un guión o un slash que separa el día, mes y año. Para extraer cada uno por separado, creamos un grupo por cada parte y los separadores los reemplazamos por un comodín
(\d\d).(\d\d).(\d\d\d\d)
📧Correos electrónicos
Los correos electrónicos están formados por 3 partes, el usuario, el @, el dominio.
Para obtener el usuario construiremos una clase “[ ]” que :
Contenga cualquier tipo de carácter alfanumérico (dígitos y/o letras)
[\w]Puede tener contener ademas punto, guión o guión bajo
[\w\.-_]Debe tener entre 5 y 30 caracteres
[\w\.-_]{5,30}Opcionalmente puede o no contener un símbolo mas "+" que debemos escapar con un \ ya que es un caracter especial
[\w\.-_]{5,30}\+?Luego le puede seguir una palabra "\w" entre {0,10} caracteres
[\w\.-_]{5,30}\+?\w{0,10}
Para obtener el dominio tenemos que controlar 2 partes, el nombre y el TLD
El dominio lo extraemos con una clase
[]que definirá que el dominio puede ser cualquier caracter alfanumérico\w, un punto o un guion medio[\w\.\-]El dominio puede tener de 3 o más caracteres
[\w\.\-]{3,}Luego, va un un punto, seguido de 2 a 5 caracteres entre la “a” y la “z” minúscula.
[\w\.\-]{3,}\.[a-z]{2,5}
Si unificamos todo en una sola expresión regular separada por un arrob, tenemos lo siguiente
[\w\.-_]{5,30}\+?\w{0,10}@[\w\.\-]{3,}\.[a-z]{2,5}

🔗URLs
Las URLs son similares a los correos electronicos, pero en lugar de tener el usuario y el arroba, se tiene el protocolo
Primero creamos un grupo para el protocolo que puede terminar con s o no
(https?)Luego viene dos puntos y dos slash que tenemos que escapar
(https?):\/\/Algunos aún tienen el www, por lo que lo agregamos
(www.)?Continuamos con el dominio, así que copiamos el ejemplo del dominio de los correos
[\w\.\-]{3,}\.[a-z]{2,5}Finalemente, puede tener o no una subpágina
(\/\w+)?
Uninficando todo, tenemos lo siguiente
(https?):\/\/(www.)?[\w\.\-]{3,}\.[a-z]{2,5}(\/\w+)?

📝Logs
Los logs dependen de la herramienta que uses así que en este ejemplo te mostraré como extraer los logs generados por rocketbot
2023-07-06 23:40:34.828902 - rocketbot - INFO - request: Robotipy : line 1 - rpalogic : evaluateIf id: 35035c05-d20d-0561-a87e-5aba8232171c - - True
Rocketbot crea sus logs de la siguiente forma
Inicia con una timestamp (fecha y hora):
(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d+)Segundo, el origen del log (rocketbot o bot):
(\w+)Tercero, el tipo de logs (INFO, TRACE, ERROR, etc):
(\w+)Luego, después de "request:" viene el nombre del robot:
(request: \w+)Sigue con la línea del comando:
line ([\d\.]{1,})Después la categoría : nombre del comando:
(\w+) : (\w+)El id particular del comando en forma de uuid, luego de la palabra id:
id: ([a-zA-Z\d\-]{1,})Finalmente, información del comando que puede venir en diferentes formatos
(.*)
La expresión regular para el log completo quedaría así:
(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d+) - (\w+) - (\w+) - (request: \w+) : line ([\d\.]{1,}) - (\w+) : (\w+) id: ([a-zA-Z\d\-]{1,}) - - (.*)
💳DNI
Si quieres validar DNI en formularios, puedes usar las siguientes expresiones regulares para Chile y Argentina
Chile — \d{1,2}.?\d{3}.?\d{3}-?\d
Argentina — \d{1,2}.?\d{3}.?\d{3}
Y eso es todo por hoy! Si conoces alguna otra expresión regular útil, escribirme un comentario para que todos podamos aprender.
Si encontraste valor en este newsletter, considera compartirlo con tu equipo ❣️
Ten una gran semana! 🚀
Daniela
 | A guest post by
|