

Xpath: Encuentra cualquier elemento en una página web
Guía de como utilizar XPath para encontrar cualquier elemento en una página web y optimizar tus robots


Hey, por acá Danilo 👋
Bienvenido a una nueva edición de Robotipy. En este articulo te enseñaré que es un Xpath, como construirlos y como puedes optimizar tus búsquedas al hacer webscraping.
Si quieres recibir estas publicaciones desde tu correo electrónico, te invito a suscribirte.
Cuando comencé a construir mis primeros robots, uno de mis mayores dolores de cabeza eran las páginas donde cambiaban los identificadores o la posición de sus elementos. Siempre tenía que recurrir a bucles + algún truco con javascript.
Cuando realicé el rpachallenge, construí un robot que leía los labels y luego escribía en el input que se encontraba debajo. Mi robot demoraba cerca de 10 segundos en completar el formulario. El robot de mi compañero José lo hacía en 1 segundo.
La diferencia entre los dos robots? José usó un xpath que iba directo al input que necesitaba. 10x más rápido su robot.
//input[@ng-reflect-name="labelPhone"]
¿Que es un xpath?
Mi definición de xpath es — el camino (path) de todas las etiquetas que tienes que recorrer para llegar a un elemento xml o html (Similar a las rutas para encontrar una carpeta o una página web) potenciado con funciones o una sintaxis similar a las expresiones regulares.
XPath (XML Path Language) es un lenguaje que permite construir expresiones que recorren y procesan un documento XML. La idea es parecida a las expresiones regulares para seleccionar partes de un texto sin atributos (plain text). XPath permite buscar y seleccionar teniendo en cuenta la estructura jerárquica del XML.
Fuente: Wikipedia
Un xpath, igual que las rutas hacia una carpeta en una terminal, tiene dos tipos de sintaxis. Absolutas y relativas
Xpath absoluto
También llamado full Xpath, es la ruta completa, desde la etiqueta raíz del documento (/html en web) e indica el paso a paso hasta llegar al elemento que se busca.
La mayoría de los navegadores tienen la opción de copiar este xpath, por lo que no ahondaremos mucho en esta sintaxis.

/html/body/div[1]/div[1]/div/div/div[5]/div[1]/div[3]
Xpath Relativo
Es la ruta, comenzando desde cualquier lugar del documento y se utiliza comenzando con dos slash (//tag). Esta sintaxis es muy útil porque te permite eliminar las partes variables de la página y puedes comenzar a buscar los elementos desde un punto fijo.
En los navegadores cuando copias el xpath, estás copiando un tipo de xpath relativo, basado en el identificador más cercano.
//*[@id="publish-main"]/div/div[5]/div[1]/div[3]/div[1]/div[3]
Sintaxis de un xpath - Etiqueta y predicado
La sintaxis básica de un xpath se conforma por tres partes: tipo de búsqueda (/ o //), la etiqueta y filtros(opcional). Esta sintaxis la podemos ir uniendo para formar xpath más complejos e ir “moviendote” entre etiquetas hasta llegar al elemento que buscas
💡Cuando hablo de etiqueta, me refiero a los tags o elementos en html. Puedes tomar un curso de básico de 10 min de html para comprender los conceptos
//etiqueta[predicado]
🔍 Tipo de búsqueda — Define si queremos buscar de forma relativa o absoluta. Si indicamos un /, significa que el elemento que queremos buscar, está en el nivel siguiente de donde nos encontramos. Mientras que si usamos //, significa que el elemento puede estar en cualquier nivel de profundidad desde donde nos encontramos
🏷️ Etiqueta — Es la etiqueta xml o html que buscamos. Ej. html, div, a, span, etc. También puedes usar carácteres especiales, como * para buscar cualquier etiqueta, o .. para referenciar la etiqueta anterior a donde estás.
⏬ Predicado— Son las reglas y condiciones que aplicamos para diferenciar una etiqueta de otra. Ej, @id="value", contains(),text(), etc
Un xpath está conformado por una secuencia de esta estructura básica. Analicemos el siguiente Xpath:
//*[@id="publish-main"]/div/div[5]/div[1]
Comienza con //, lo que significa que lo que viene a continuación puede estar en cualquier lugar de la página
Tiene un *, lo que significa que puede ser cualquier etiqueta html
Continúa con información entre [ ], esto significa que tendrá un filtro para diferenciar la etiqueta del punto 2, ue hasta ahora puede ser cualquiera
@id="publish-main": Significa que la condición es que el atributo id del elemento, debe tener el valor de publish-main
Si leemos todo junto para la primera parte del xpath, tenemos que: busco en cualquier parte de la página, un elemento que puede ser de cualquier etiqueta, pero que su id sea publish-main
Luego tenemos otros xpath concatenados /div/div[5]/div[1].
Los / significan que serán búsquedas absolutas, o sea, /div es el siguiente div después de //*[@id="publish-main"]
Luego, y de forma repetitiva hasta el final, tenemos /div[numero]. Esto lo podemos leer como: de forma absoluta al div anterior, busco la etiqueta div siguiente y de todos los resultados, quiero el que esté en la posición “número”
Si vez la imagen de abajo, tenemos marcado el div con el id publish-main, luego la etiqueta siguiente es un div y dentro de éste, hay varios div más. El xpath que estamos analizando, nos dice que el div por donde pasaremos, es el div número 5 y finalmente, llegaremos al div número 1 (el marcado en amarillo, con clase “post typography container”

El xpath que analizamos fue copiado directamente del navegador y usa el “id” como punto de inicio para crear el xpath. Una forma diferente para crear nuestro xpath es yendo directo a lo que queremos: //div[@class="post typography container"].
Tipos de filtros
Lo que llamaremos filtros, son funciones y/o condiciones que “filtran” los resultados obtenidos al crear una xpath solo con etiquetas. Estas pueden combinarse para crear xpath muy complejos, igual como las expresiones regulares. A continuación los más usados por mi.
Filtro por attributo
Este tipo de filtro es el más común o básico y utiliza el atributo del elemento para condicionar la búsqueda. En los ejemplos anteriores utilizamos el atributo id y class.
//tag[@attributo=”value”]
Si tomamos como ejemplo el login de facebook, podemos filtrar el input de email por el atributo “name” y usar un xpath como: //input[@name="email"]

Filtro por texto
Este filtro es similar al anterior, pero en lugar de usar un atributo, usaremos el texto que contiene la etiqueta. Para esto, en lugar de usar @attributo, usaremos el método o keyword text().
//tag[text()=”value”]
Siguiendo con el ejemplo de Facebook, podemos encontrar el botón de iniciar sesión con el xpath: //button[text()="Iniciar sesión"]
⚠️ Para usar este xpath, tienes que asegurarte que el idioma de la página no cambie. Para la versión de facebook en inglés, el texto es “Log In”

Filtro con functiones
Existen muchas funciones para filtrar y todo el tiempo aprendo una nueva. Acá te enseñaré las 3 que más he usado
contains()
Esta función, como su nombre lo dice, permite buscar por un valor contenido en otro. Por ejemplo, la palabra "nacional" existe dentro de la palabra "internacional".
Esta función recibe dos parámetros, el filtro (attributo, text(), etc.) y el sub valor a encontrar.
//etiqueta[contains(@atributo, ‘valor’)]
Tomemos como ejemplo la página de ArenaRPA, y supongamos que la página puede estar en inglés o español. Si quisiéramos dar click en el botón para descargar el excel usando un filtro por texto, podríamos usar un xpath así: //a[text()="Descargar Excel"]
Si la página cambia de idioma, el botón diría algo como “Download Excel”, haciendo que falle la búsqueda. Para este caso usamos el contains(), buscamos una etiqueta "a" que contenga la palabra "Excel", quedando un xpath así: //a[contains(text(), "Excel")]
No solo funciona con text(), puedes usar atributos, como un href: //a[contains(@href, “/crazy-form“)

not()
Esta función nos sirve para negar la condición que estemos usando, o en otras palabras, indica al xpath que haga lo contrario de lo que indicamos. Esta función se usa normalmente como complemento de otro filtro.
//etiqueta[not(filtro)]
Si seguimos tomando el ejemplo de ArenaRPA, y quisieramos encontrar todas las etiquetas a que no tengan el atributo href (como el botón "Descargar Excel" o "Iniciar Reto") podríamos usar un xpath así: //a[not(@href)]

starts-with()
Esta función es similar al contains(), recibe los mismos parámetro, pero en lugar de buscar un texto contenido en otro, busca un texto que comienza con lo que le indiquemos.
//etiqueta[starts-with(@attributo, "value")]
Como ejemplo, hagamos webscraping a Twitter y busquemos todos los tweets que comiencen con el texto "Web scraping".
Nuestro xpath quedaría así: //*[starts-with(text(), 'Web scraping')]

Filtro por nombre de etiqueta
Este filtro puede parecer innecesario, ya que los xpath por si mismo ya contienen el nombre de la etiqueta, pero es muy útil cuando se usa con otras funciones. Los casos de usos para este tipo de filtro son páginas con etiquetas personalizadas
//*[name()="etiqueta"]
En la página de rpachallenge, tenemos una etiqueta propia de la página llamada "rpa1-field", el xpath para encontrarla es el siguiente: //rpa1-field. Si lo vemos así, el keyword name() no es necesario.
Ahora supongamos que lo que está después del rpa1- es variable. Para estos casos nos sirve el filtro por etiqueta. En conjunto con el filtro starts-with, podemos crear un xpath así: //*[starts-with(name(),"rpa1-")]
No confundir con el attributo name, que vimos para el ejemplo de facebook. Para buscar por el attributo se debe usar @name

Filtro con multiples condiciones
Cuando vimos la función contains(), tuvimos el caso de tener un botón en dos idiomas. Una alternativa para esos casos es usar el keyword or para buscar un elemento si cumple una condición u (or) otra.
//etiqueta[filtro1 or filtro2]
En el caso de ArenaRPA, podemos usar el xpath así: //a[text()=" Descargar Excel " or text()="Download Excel"]

Al igual que un or, podemos usar un and, para crear un xpath que cumpla dos condiciones a la vez
//etiqueta[filtro1 and filtro2]
Este es el xpath para encontrar el botón de login de Facebook usando una condición and: //*[text()="Log In" and @name="login"]. Esto lo podemos leer como, un elemento que tenga el texto "Log In" y tenga el atributo name igual a "login"

Filtro por orden o posición
Este tipo de filtro lo vimos en los primeros ejemplos. Simplemente tenemos que indicar el orden del elemento que queremos buscar cuando existe más de un mismo resultado.
/*/tag[orden]
Este tipo de filto se utiliza con una búsqueda absoluta, por lo que siempre viene después de un solo slash (/tag). Para encontrar el primer cuadro de resultados en una busqueda en google, este es el xpath: //*[@id="rso"]/div[1]/div/div/div/div[1].
La útlima parte del xpath indica que se debe tomar el primer div que se encuentre. Si no se indica el 1, encontrará dos resultados

Axes o Ejes
Los Axes (o ejes en español) son una relación que se apoya del elemento actual y se utiliza para localizar nodos relativos a este. El uso de estos sería:
Buscas un elemento creando un xpath y luego en base a ese resultado, nos moveremos al nivel que queramos
//xpath//axe::tag
Existen más de 10 axes diferentes, pero en este post veremos los que más he utilizado.
👶child::
Este axes te permite encontrar los elementos hijos del elemento donde te encuentras.
//*[@ng-reflect-dictionary-value="Phone Number"]//child::input
El xpath anterior es utilizado para encontrar el campo de número de teléfono en el rpachallenge. Este se lee así:
Encuentra una etiqueta que tenga el atributo ng-reflect-dictionary-value con el valor "Phone Number". Una vez encuentras ese elemento, busca los hijos con la etiqueta input

🧓ancestor::
Este axes encuentra todos los ancestros (padre, abuelo, etc.) del elemento donde te encuentres
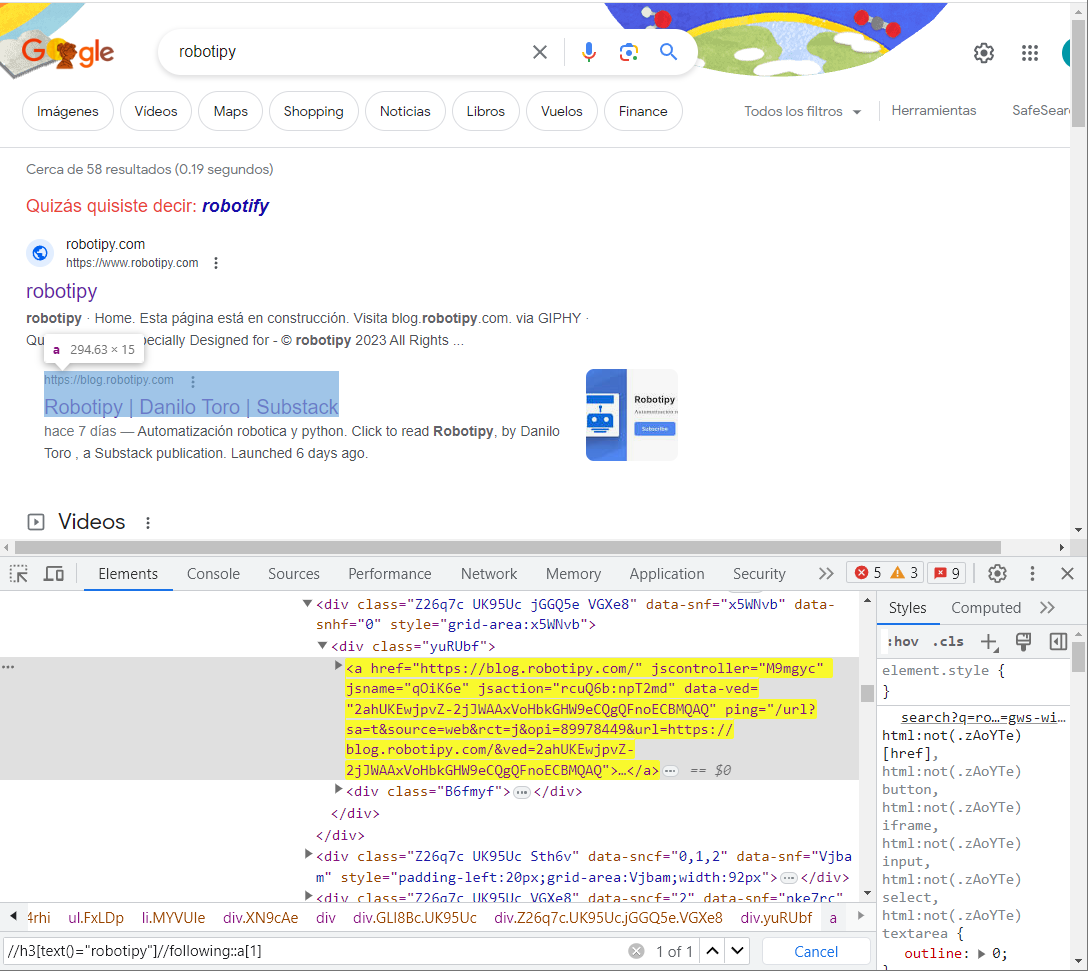
//h3[text()="text"]//ancestor::a
El xpath anterior es utilizado para encontrar el link del primer resultado de una búsqueda en google. Si la búsqueda es "robotipy” se leería así:
Encuentra una etiqueta h3 con el texto igual a "robotipy" y desde ese elemento, busca un ancestro con la etiqueta a

👨parent::
Este eje es similar a ancestor::, con la diferencia que solo encuentra el padre del elemento actual. Ignora cualquier otra ascendencia.
Siguiendo el ejemplo anterior, el xpath es el siguiente:
//h3[text()="robotipy"]//parent::a

⏭️following::
Este axes encuentra todo lo que hay en el documento después del elemento actual. Si se requiere encontrar un elemento en particular, se tiene que combinar con algún otro filtro.
//h3[text()="robotipy"]//following::a[1]
El xpath anterior, también busca un h3 con el texto "robotipy", y una vez encontrado el elemento, buscará cualquier etiqueta "a" que venga a continuación. Para filtrar por un único valor, se utiliza [1] para encontrar el primer resultado
Y esto es todo lo que necesitas saber para comenzar con xpath. Faltan muchos otros métodos y axes que podrías aprender pero el post se haría eterno.
Te dejo algunos recursos que he utilizado para ir aprendiendo sobre esto y pronto publicaré alguna ayuda resumida para que tengas como guía.
Si encontraste valor en este newsletter, considera compartirlo con tu equipo
Ten una gran semana! 🚀
Danilo
 | A guest post by
|